
Nessa aula iremos entender melhor como funciona o algoritmo KNN e como implementar um código que utiliza essa técnica para classificação. No reconhecimento de padrões, o algoritmo de k-vizinhos mais próximos (K – Nearest Neighbours – KNN) é um método não paramétrico usado para classificação e regressão. Em ambos os casos, a entrada consiste nos k exemplos de treinamento mais próximos no espaço de recursos. A saída depende se o KNN é usado para classificação ou regressão:
Na classificação KNN, a saída é uma associação de classe, ou seja, quando usamos o algoritmo de KNN um objeto é classificado de acordo com os seus vizinhos. Geralmente, a classe atribuída é aquela que é a mais comum entre seus k vizinhos mais próximos. Quando o usuário define que k = 1, então o algoritmo entende que o objeto da mesma classe que aquele único vizinho mais próximo. Quando o K é maior que 1, é calculada a média dos valores de seus k vizinhos mais próximos só então é possível classificar a nova ocorrência.
Vamos ver um exemplo simples, considere o seguinte gráfico:
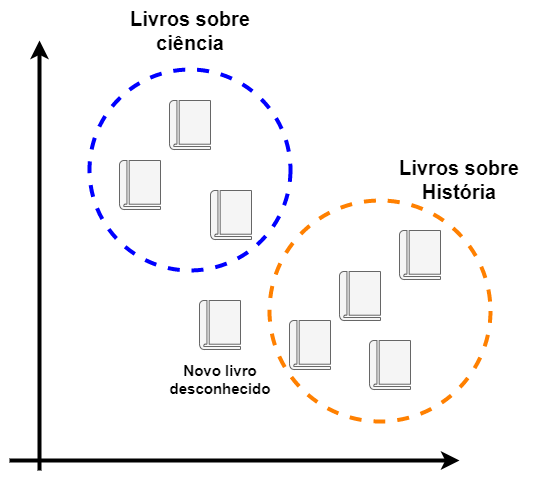
Na figura acima podemos ver claramente que existem dois grupos bem definidos (livros de história e ciências). Porém, um novo exemplar foi inserido no nosso gráfico e ele é desconhecido. O algoritmo KNN poderia facilmente classificar esse novo livro baseado apenas em seus vizinhos.
Vamos imaginar então que escolhemos avaliar os 5 vizinhos mais próximos:
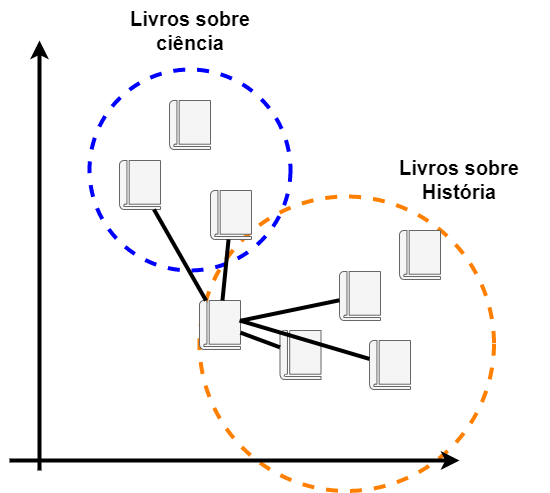
Ao realizar a análise dos 5 vizinhos mais próximos descobrimos que existem 3 deles que são de história e apenas 2 que são de ciências. Assim, nosso novo exemplar é classificado como um livro de história.
Quando falamos de KNN, estamos nos referindo a um tipo de aprendizado baseado em instância, ou aprendizagem preguiçosa (lazy learning), em que a função é apenas aproximada localmente e toda a computação é adiada até a classificação.
O algoritmo KNN está entre os mais simples de todos os algoritmos de aprendizado de máquina. Tanto para classificação como para regressão, uma técnica útil pode ser usada para atribuir peso às contribuições dos vizinhos, de modo que os vizinhos mais próximos contribuam mais para a média do que os mais distantes. Por exemplo, um esquema de ponderação comum consiste em dar a cada vizinho um peso de 1 / d, onde d é a distância até o vizinho. Os vizinhos são retirados de um conjunto de objetos para os quais a classe (para classificação KNN) ou o valor da propriedade do objeto (para regressão k-NN) é conhecido. Isso pode ser considerado como o conjunto de treinamento para o algoritmo, embora nenhuma etapa de treinamento explícita seja necessária.
Esse texto foi adaptado daqui.
Exemplo prático
Agora vamos iniciar nosso exemplo prático de implementação do KNN, portanto vamos conhecer a base de dados usada e também ver um pouco de como implementar usando python.
base de dados
O algoritmo de KNN precisa de exemplos para que se possa calcular as distâncias e prever qual classe o novo exemplar pertence. No nosso exemplo iremos utilizar um dataset experimental que trata da classificação de tipos de filmes.
Imagine que queremos saber se um filme é de terror ou não, para isso reunimos algumas características de filmes:
- O filme é engraçado? (nota de 0 a 5)
- O filme é dramático? (nota de 0 a 5)
- O filme é assustador? (nota de 0 a 5)
- O filme é nojento? (nota de 0 a 5)
- O filme é futurista? (nota de 0 a 5)
Então temos o dataset:
filme1 = [0,2,5,5,0] filme2 = [5,0,0,0,5] filme3 = [0,5,5,5,0]
isTerror = [1,0,1]
A variável is terror contém um vetor contendo as classes que são atribuídas a esse tipo de filme.
Implementação do KNN em python
Para utilizar o KNN no python, nos beneficiaremos do pacote do scikit-learn que já possui o KNN implementado. Precisamos apenas passar os parâmetros da forma correta.
# filmes [ engraçado, dramatico, assustador, nojento, futurista]
filme1= [0,3,5,5,0]
filme2= [5,0,0,0,0]
filme3= [5,5,0,0,0]
filme4=[0,0,5,5,0]
isTerror = [1,0,0,1]
X = [filme1,filme2,filme3,filme4]
y = isTerror
from sklearn.neighbors import KNeighborsClassifier
neigh = KNeighborsClassifier(n_neighbors=2)
neigh.fit(X, y)
novoFilme = [[0,1,5,5,0]]
if neigh.predict(novoFilme) == 1 :
print("É de terror")
else:
print("não é de terror")
Nesse caso treinamos nosso modelo para identificar se o filme que será informado é de terror ou não. Assim fornecemos alguns exemplos já classificados e o algoritmo consegue prever a classificação com um certo nível de acerto. Lembrando que o número de vizinhos é importante para definir quantos vizinhos são necessários para classificar o novo elemento.


