
Nesse post você vai compreender o que é a regressão logística e como ela funciona. Nosso objetivo aqui não é aprofundar nos fundamentos matemáticos e toda a teoria em volta desse tema, mas sim mostrar uma visão mais prática de como você pode utilizar essa técnica.
Vamos explorar ainda nesse post uma simulação de como a regressão logística pode ser aplicada para resolver problemas reais. Utilizaremos a linguagem python e pacotes open source que você pode executar quando quiser no seu ambiente. Vale lembrar que estou utilizando o ambiente Anaconda e a IDE spyder.
O que é regressão logística
Regressão logística pode ser definido como uma técnica estatística que busca produzir (usando um conjunto de observações) um modelo que possibilita predizer os valores tomados por uma variável categórica. Traduzindo isso pra uma linguagem mais simples, podemos dizer que a regressão logística é parecido com a regressão linear, no entanto, quando falamos de regressão linear o valor de Y assume um valor específico, já na regressão logística temos a variável Y assumindo um valor Binário (0 – fracasso / 1 – sucesso). Essa técnica é recomendada para situações onde a variável dependente é binária.
Portanto, podemos concluir que Regressão Logística busca estimar a probabilidade da variável dependente assumir um determinado valor em função dos outros valores.
Quais são as vantagens de usar regressão logística?
Existem algumas vantagens em usar esse tipo de regressão, entre elas:
- Os resultados são mostrados em formato de probabilidade.
- É bastante fácil classificar indivíduos em categorias.
- Precisa apenas de um pequeno número de suposições para realizar as predições.
- Possui um alto grau de confiabilidade dos resultados.
Exemplos práticos de utilização da regressão logística
Apesar de parecer algo muito inacessível, a regressão logística é bastante utilizada em ciências médicas e sociais. Podem existir também outros nomes: modelo logístico, modelo logit, ou classificador de máxima entropia.
No campo da medicina é possível determinar determinar os conjunto de fatores que torna um grupo de indivíduos doentes quando comparamos com indivíduos saudáveis. Por exemplo, imagine que temos uma variável chamada (0 – saudável | 1 – doente), usando a regressão é possível analisar quais conjuntos de fatores (obesidade, tabagismo, genética, etc.) pode alterar essa variável.
Agora imagine que você é dono de uma seguradora, seria bem interessante conseguir determinar quais são os fatores que mais influenciam no acontecimento de acidentes. Outra faceta desse problema acontece muito em instituições financeiras, com esse tipo de algoritmo você poderia detectar os grupos de risco para a subscrição de um crédito.

Exemplo de regressão logística: será que você sobreviveria ao Titanic?
Uma das aplicações mais “malucas” que ví recentemente foi uma propondo calcular a chance de você sobreviver ao acidente do Titanic. Se você assistiu o filme clássico do desastre, você deve lembrar que existiam classes sociais diferentes dentro do mesmo barco. Existiam os trabalhadores que movimentavam as caldeiras de carvão, empregados da primeira classe e também a querida 1º classe composta de ricos. Outro ponto sensível era se você era mulher ou homem e também a idade dos tripulantes.
Esse artigo construiu um modelo baseado nos dados do Titanic e apontou vários dados interessantes. Por exemplo, a sobrevivência de mulheres foi 12x maior do que a dos homens. Do acidente, só sobreviveram 40% da população do navio, no entanto, dos sobreviventes mais de 60% eram mulheres.
Eu calculei minha probabilidade de estar morto nesse acidente, tenho 30 anos, 2º classe e sou homem. Esse é o resultado:

Exemplo de regressão logística em python
Para mostrar um exemplo simples de como a regressão logística pode ser usada, vamos utilizar um dataset bastante pequeno. Abaixo, temos uma tabela mostrando se um aluno será admitido ou não em um programa de pós-graduação. Os parâmetros são notas da POSCOMP (0 – 100), pontuação em testes de inglês (0 – 10), número de artigos publicados (inteiros) e por fim se ele foi admitido (1) ou não (0).
| POSCOMP | Inglês | Artigos publicados | Admitido |
| 89 | 8 | 5 | 1 |
| 39 | 5 | 1 | 0 |
| 40 | 2 | 1 | 0 |
| 14 | 1 | 0 | 0 |
| 26 | 4 | 1 | 0 |
| 57 | 8 | 2 | 1 |
| 46 | 6 | 1 | 0 |
| 35 | 2 | 2 | 0 |
| 67 | 4 | 1 | 1 |
| 86 | 6 | 3 | 1 |
| 54 | 3 | 4 | 1 |
| 34 | 4 | 1 | 0 |
| 26 | 1 | 2 | 0 |
| 67 | 8 | 1 | 1 |
| 36 | 4 | 2 | 0 |
| 34 | 1 | 1 | 0 |
| 13 | 2 | 0 | 0 |
| 67 | 5 | 2 | 1 |
| 54 | 6 | 2 | 0 |
| 31 | 3 | 1 | 0 |
| 75 | 8 | 5 | 1 |
| 69 | 9 | 6 | 1 |
| 98 | 10 | 10 | 1 |
| 90 | 9 | 11 | 1 |
A seguir, vamos começar nosso código em python, primeiro vamos importar as bibliotecas.
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn import metrics
import seaborn as sn
import matplotlib.pyplot as plt
Depois precisamos importar os dados para o python:
df = pd.read_excel('dados.xlsx')
df.head()
A seguir, vamos dividir nossos dados em teste e treinamento:
X = df[['POSCOMP', 'Inglês','Artigos publicados']] y = df['Admitido'] X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.25,random_state=0)
Agora, está na hora da mágica acontecer, vamos treinar nosso classificador:
logistic_regression= LogisticRegression()
logistic_regression.fit(X_train,y_train)
y_pred=logistic_regression.predict(X_test)
Depois de treinado podemos visualizar a matriz de confusão:
confusion_matrix = pd.crosstab(y_test, y_pred, rownames=['Actual'], colnames=['Predicted'])
sn.heatmap(confusion_matrix, annot=True)
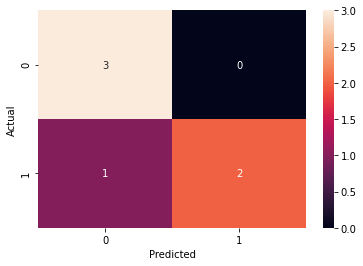
Podemos ainda calcular a acurácia do nosso modelo:
print('Accuracy: ',metrics.accuracy_score(y_test, y_pred))
plt.show()
Nesse caso a acurácia permanece em 0.83333
Tá, mas o que isso significa?
Bom, com todo esse código nós conseguimos prever com 83% de acurácia se você entraria ou não em um programa de pós-graduação baseado nesses parâmetros. Imagine por exemplo que você tirou 65 na POSCOMP, possui um inglês intermediário (6) e 2 artigos publicados.
teste = {'POSCOMP': 65, 'Inglês': 6, 'Artigos publicados': 2}
dft = pd.DataFrame(data = teste,index=[0])
print(dft)
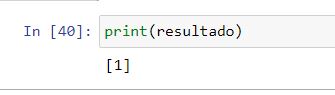
resultado = logistic_regression.predict(dft)
Usando esse código podemos ver que o resultado desse teste é que “sim” você passaria no processo seletivo.




excelente explicação! muito obrigado por me ajudar a entender.
Opa! eu que agradeço sua confiança no website!
Abraços
Ótima publicação!
Com minha base de dados recebi erro ao executar logistic_regression.fit(X_train,y_train). Descobri que há um limitante conhecido no numero de iterações do sklearn nesta função
A solução foi escalonar os valores de X
from sklearn.preprocessing import StandardScaler
scaler_salary = StandardScaler()
X = scaler_salary.fit_transform(X)
Top demais Felipe!
Obrigado por compartilhar seu conhecimento com a comunidade!
Abraços