
Nesse post você vai conhecer melhor um dos algoritmos mais famosos do processamento de linguagem natural, o TFIDF ou TF-IDF e como implementar ele usando o Python. Mas antes de qualquer coisa, vamos compreender o que é esse “Term Frequency (TF)”.
Quer saber mais sobre Processamento de Linguagem Natural? Veja nossos artigos gratuitos.
O que é Term Frequency (TF)?
Essa técnica foi explicada na nesse post utilizando a nomenclatura “saco de palavras” para nos referir ao resultado final do algoritmo. É claro que o saco de palavras é apenas uma forma de processar texto e que irá permitir análises posteriores. Porém, sabemos que as palavras que possuem maior frequência em um texto tendem a ser mais importantes para identificar a área que o texto está abordando. O modelo que utiliza a frequência de termos (TF) permite sabermos instantaneamente qual os termos mais frequentes.
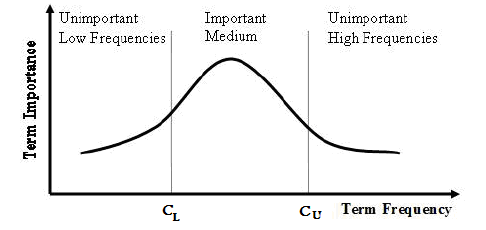
O problema de utilizar o Term Frequency
A frequência de termos quando utilizada pode ser eficaz, porém alguns termos que não são eliminados podem atrapalhar a análise. Existem algumas palavras que são muito comuns e se repetem por todos os documentos de texto. Elas possuem significado e não podem ser eliminadas no pré-processamento.
Para realizar uma análise mais precisa do corpus utilizamos não mais apenas a frequência simples e sim a frequência multiplicada pelo inverso da frequência considerando o conjunto completo de documentos. Por exemplo: imagine um conjunto de 150 documentos no qual a palavra “claro”: aparece em 149 documentos, “médico”: em 98 , “plantas”: em 89.
A técnica do TF-IDF desconsidera as palavras com maior frequência entre documentos e dá maior importância para as palavras que tem maior frequência e não estão presentes em muitos documentos.
Implementando o TF-IDF em python
Antes de implementar o TFIDF, como de costume vamos importar os módulos para pré-processamento e o NLTK:
import nltk import re # inserimos um texto aleatório texto = """France, in Western Europe, encompasses medieval cities, alpine villages and Mediterranean beaches. Paris, its capital, is famed for its fashion houses, classical art museums including the Louvre and monuments like the Eiffel Tower. The country is also renowned for its wines and sophisticated cuisine. Lascaux’s ancient cave drawings, Lyon’s Roman theater and the vast Palace of Versailles attest to its rich history."""
A seguir dividimos o texto em sentenças:
# Divide o texto em frases dataset = nltk.sent_tokenize(texto)
Realizamos o pré-processamento:
#realizando o pré-processamento
for i in range (len(dataset)):
dataset[i] = dataset[i].lower() #converte todas as palavras para letras minusculas
dataset[i] = re.sub(r'W', ' ', dataset[i]) # troca tudo que não for uma palavra para um espaço
dataset[i] = re.sub(r's+', ' ', dataset[i]) # troca tudo que for quebras de linha para um espaço simples
print (dataset)
['france in western europe encompasses medieval cities alpine villages and mediterranean beaches ', 'paris its capital is famed for its fashion houses classical art museums including the louvre and monuments like the eiffel tower ', 'the country is also renowned for its wines and sophisticated cuisine ', 'lascaux s ancient cave drawings lyon s roman theater and the vast palace of versailles attest to its rich history ']
Criando um histograma:
# criando um histograma
word2count = {}
for data in dataset:
words = nltk.word_tokenize(data)
for word in words:
if word not in word2count.keys():
word2count[word] = 1
else:
word2count[word] += 1
print (word2count)
{'france': 1, 'in': 1, 'western': 1, 'europe': 1, 'encompasses': 1, 'medieval': 1, 'cities': 1, 'alpine': 1, 'villages': 1, 'and': 4, 'mediterranean': 1, 'beaches': 1, 'paris': 1, 'its': 4, 'capital': 1, 'is': 2, 'famed': 1, 'for': 2, 'fashion': 1, 'houses': 1, 'classical': 1, 'art': 1, 'museums': 1, 'including': 1, 'the': 4, 'louvre': 1, 'monuments': 1, 'like': 1, 'eiffel': 1, 'tower': 1, 'country': 1, 'also': 1, 'renowned': 1, 'wines': 1, 'sophisticated': 1, 'cuisine': 1, 'lascaux': 1, 's': 2, 'ancient': 1, 'cave': 1, 'drawings': 1, 'lyon': 1, 'roman': 1, 'theater': 1, 'vast': 1, 'palace': 1, 'of': 1, 'versailles': 1, 'attest': 1, 'to': 1, 'rich': 1, 'history': 1}
Realizamos a ordenação:
# biblioteca para ordenação import heapq # ordena a lista para saber qual é a palavra que mais se repete freq_words = heapq.nlargest(50,word2count, key=word2count.get) print (freq_words)
['and', 'its', 'the', 'is', 'for', 's', 'france', 'in', 'western', 'europe', 'encompasses', 'medieval', 'cities', 'alpine', 'villages', 'mediterranean', 'beaches', 'paris', 'capital', 'famed', 'fashion', 'houses', 'classical', 'art', 'museums', 'including', 'louvre', 'monuments', 'like', 'eiffel', 'tower', 'country', 'also', 'renowned', 'wines', 'sophisticated', 'cuisine', 'lascaux', 'ancient', 'cave', 'drawings', 'lyon', 'roman', 'theater', 'vast', 'palace', 'of', 'versailles', 'attest', 'to']
# criando o IDF
import numpy as np
word_idfs = {}
for word in freq_words:
doc_count = 0
for data in dataset:
if word in nltk.word_tokenize(data):
doc_count += 1
word_idfs[word] = np.log((len(dataset)/doc_count)+1)
print (word_idfs)
# calculando a frequencia de cada palavra nos documentos
tf_matrix = {}
for word in freq_words:
doc_tf = []
for data in dataset:
frequency = 0
for w in nltk.word_tokenize(data):
if w == word:
frequency += 1
tf_word = frequency/len(nltk.word_tokenize(data))
doc_tf.append(tf_word)
tf_matrix[word] = doc_tf
print (tf_matrix)
Por fim devemos calcular o TF-IDF e colocar na matriz:
# TF-IDF cálculo
tfidf_matrix = []
for word in tf_matrix.keys():
tfidf = []
for value in tf_matrix[word]:
score = value * word_idfs[word]
tfidf.append(score)
tfidf_matrix.append(tfidf)
print (tfidf_matrix)




Olá. Tentei rodar o seu código e recebi o seguinte erro:
Traceback (most recent call last):
File "", line 1, in
tf_idf_sent(texto)
File "", line 45, in tf_idf_sent
score = value * word_idfs[word]
NameError: name 'word_idfs' is not defined
De fato, a variável word_idfs não aparece em lugar algum do código. O que devemos fazer para calcular o IDF? Obrigado, abs.
Olá gustavo, o post foi corrigido com o código completo… acesse também o código no github, foi testado e está funcionando normalmente. O link está no fim do post, é só clicar no botão