Como funciona o algoritmo de Agrupamento Hierárquico


Nessa aula iremos aprender o que é o agrupamento hierárquico e como ele pode ser implementado utilizando o pacote do python scikit-learn. Na mineração de dados e estatística, o agrupamento hierárquico (também chamado de análise hierárquica de cluster ou HCA ) é um método de análise de cluster que procura construir uma hierarquia de clusters. As estratégias para agrupamento hierárquico geralmente se enquadram em dois tipos:
- Agglomerative : Esta é uma abordagem “de baixo para cima “: cada observação começa em seu próprio cluster, e pares de clusters são mesclados à medida que se sobe na hierarquia.
- Divisivo : Essa é uma abordagem “de cima para baixo “: todas as observações iniciam em um cluster e as divisões são executadas recursivamente à medida que se desce a hierarquia.
Aprenda mais sobre ciência de dados com nosso conteúdo gratuito.
Em geral, as mesclagens e divisões são determinadas de maneira gulosa. Os resultados do agrupamento hierárquico são geralmente apresentados em um dendrograma.

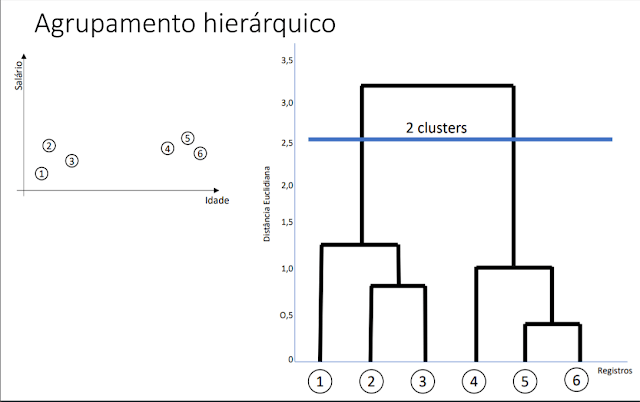
Implementação do cluster hierárquico no python
O primeiro passo é importar as bibliotecas necessárias para criar o dendrograma e realizar o clustering:
import matplotlib.pyplot as plt from scipy.cluster.hierarchy import dendrogram, linkage from sklearn.cluster import AgglomerativeClustering from sklearn.preprocessing import StandardScaler
O próximo passo é simplesmente realizar a criação da base de dados que utilizaremos como exemplo:
x=[20, 27, 21, 37, 46, 53, 55, 47, 52, 32, 39, 41, 39, 48, 48]
y=[1000,1200,2900,1850,900,950,2000,2100,3000,5900,4100,5100,7000,5000,6500]
#plt.scatter(x,y)
base = np.array([[20,1000],[27,1200],[21,2900],[37,1850],[46,900],
[53,950],[55,2000],[47,2100],[52,3000],[32,5900],
[39,4100],[41,5100],[39,7000],[48,5000],[48,6500]]) Então, podemos gerar o dendrograma indicando o numero de clusters:
scaler = StandardScaler()
base = scaler.fit_transform(base)
dendrograma = dendrogram(linkage(base, method = 'ward'))
plt.title('Dendrograma')
plt.xlabel('Pessoas')
plt.ylabel('Distância Euclidiana')
hc = AgglomerativeClustering(n_clusters = 3, affinity = 'euclidean', linkage = 'ward')
previsoes = hc.fit_predict(base) 
A seguir podemos criar o scatterplot dividindo os pontos em 3 clusters:
plt.scatter(base[previsoes == 0, 0], base[previsoes == 0, 1], s = 50, c = 'red', label = 'Cluster 1')
plt.scatter(base[previsoes == 1, 0], base[previsoes == 1, 1], s = 50, c = 'blue', label = 'Cluster 2')
plt.scatter(base[previsoes == 2, 0], base[previsoes == 2, 1], s = 50, c = 'green', label = 'Cluster 3')
plt.xlabel('Idade')plt.ylabel('Salário')plt.legend() 

Esse post foi modificado em 29 de dezembro de 2021 13:29