
Ler PDF com Python é possível e também bastante fácil a medida que usamos bibliotecas especializadas nessa tarefa. Algumas delas são gratuitas e estão disponíveis nos repositórios do Python (ex. pypdf2), além disso, existe a possibilidade de extrair dados de arquivos PDF usando Python. O tipo de arquivo PDF foi criado com o propósito de não ser editável, no entanto, muitas vezes esses arquivos guardam informações muito importantes e é preciso extrair e manipular essas informações.
Imagine, por exemplo, que você conseguiu uma lista telefônica em formato PDF, porém, você precisa atualizar os números. Não parece um problema complexo, no entanto, dependendo do tamanho dessa lista, esse trabalho torna-se praticamente impossível de ser executado.
Até mesmo os programadores que possuem mais domínio de várias tecnologias, as vezes, também travam algumas batalhas com esse tipo de arquivo. Seria o sonho de qualquer um que os dados estivessem em bases de dados lineares como, por exemplo, um arquivo CSV ou então até mesmo um XLSX. Considerando que nem sempre isso é possível, nesse post iremos mostrar algumas alternativas interessantes para realizar a leitura de documentos PDF e editá-los de maneira eficiente.
1- Utilizando ferramentas online
A primeira forma de converter esses documentos e torná-los acessíveis para a linguagem Python é utilizar um conversor online. O SmallPDF é um site completamente dedicado a tratar o formato PDF incluindo a conversão para formatos como DOCX ou XLSX.
Para utilizá-lo, basta acessar o site e fazer upload da sua tabela:
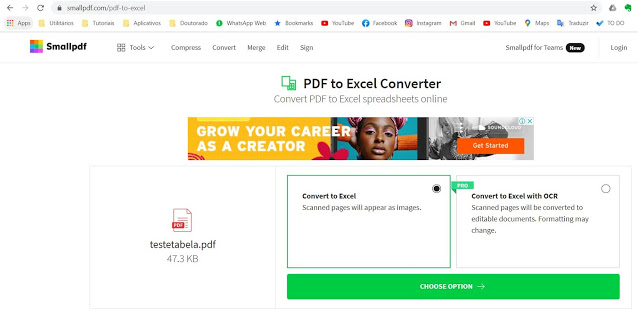
É importante perceber que o site avisa que essa conversão irá traduzir páginas scanneadas como imagens apenas. A versão PRO utiliza um software de OCR para converter imagens para texto automaticamente. Quando você utiliza tabelas criadas no próprio Word, por exemplo, a conversão é feita perfeitamente. A seguir, você pode realizar o download do documento já convertido para o formato do Excel.
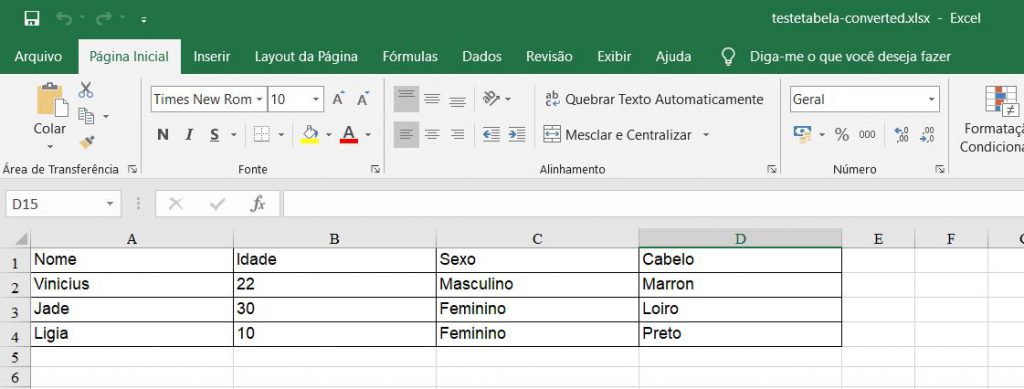
Um dos problemas desse website é que ele possui cotas de conversão, ou seja, você poderá fazer algumas conversões gratuitamente e depois ele solicitará pagamento. Além disso, ele é mais indicado caso você queira fazer a conversão de um único documento e não uma família de documentos.
Ao gerar o documento XLSX, o Pandas consegue realizar a leitura desse documento tranquilamente usando o seguinte trecho de código:
dfs = pd.read_excel("YOUR_FILE_NAME", sheet_name="SHEET_NAME")
2- Como usar a biblioteca PyPDF2 para extrair dados de um PDF
Caso você não goste de utilizar conversores online, você pode ler PDF usando o Python com a biblioteca PyPDF2. Essa biblioteca busca encontrar o texto de um PDF e torná-lo acessível ao desenvolvedor.
Para utilizá-la é necessário primeiramente instalar a biblioteca via PIP ou Conda:
pip install pypdf2
conda install -c conda-forge pypdf2
Em seguida, você poderá realizar a leitura do seu arquivo, veja o exemplo a seguir:
# importa as bibliotecas necessárias
import PyPDF2
import re
# Abre o arquivo pdf
# lembre-se que para o windows você deve usar essa barra -> /
# lembre-se também que você precisa colocar o caminho absoluto
pdf_file = open('PATH_TO_YOUR_FILE/holerite1.pdf', 'rb')
#Faz a leitura usando a biblioteca
read_pdf = PyPDF2.PdfFileReader(pdf_file)
# pega o numero de páginas
number_of_pages = read_pdf.getNumPages()
#lê a primeira página completa
page = read_pdf.getPage(0)
#extrai apenas o texto
page_content = page.extractText()
# faz a junção das linhas
parsed = ''.join(page_content)
print("Sem eliminar as quebras")
print(parsed)
# remove as quebras de linha
parsed = re.sub('n', '', parsed)
print("Após eliminar as quebras")
print(parsed)
print("nPegando apenas as 20 primeiras posições")
novastring = parsed[0:20]
print(novastring)
O código apresentado acima apresenta alguns exemplos de como utilizar expressões regulares para pré-processar o texto que foi extraído. Este pré-processamento é essencial, visto que o texto extraído apresenta vários caracteres desnecessários. Veja como um texto plano é exibido perfeitamente usando essa biblioteca:
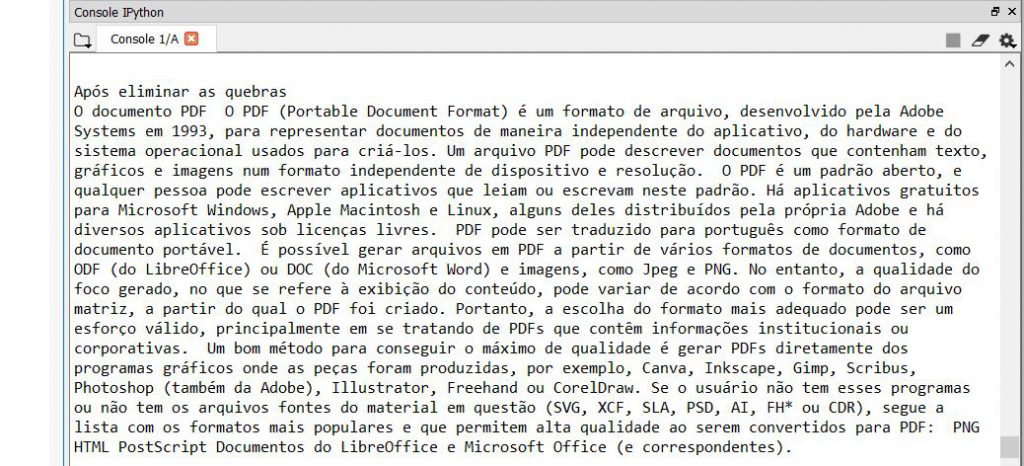
Uma limitação dessa biblioteca é que ela não lida muito bem com tabelas. O resultado ao fazer a leitura de tabelas é bastante confuso e quase ilegível. Por isso, vamos mostrar uma alternativa quando você precisa ler uma tabela usando Python.
3- Como usar a biblioteca Tabula para ler tabelas com Python
O Tabula é a biblioteca perfeita para quando você precisa ler uma tabela dentro de um documento PDF. No exemplo abaixo você verá como realizar essa importação:
#importando tabelas em pdf usando o pytabula
from tabula import read_pdf
# faz a leitura de uma tabela complexa
holerite = read_pdf("PATH_TO_YOUR_FILE/holerite1.pdf")
# claramente o resultado mostra dataframe bastante mal formado. A ferramenta tem dificuldade de
# compreender como a tabela é formada e transforma-la em algo manipulável.)
# faz a leitura de uma tabela comum
tabelaComum = read_pdf("PATH_TO_YOUR_FILE/testetabela.pdf")
# bastante fácil de compreender e manipular os dados
#Exemplos:
# retorna a primeira linha da tabela completa
tabelaComum.iloc[0]
# pega o primeiro dado da tabela
tabelaComum.iloc[0][0]
# exibe todos os nomes da (primeira coluna)
tabelaComum['Nome']
# exibe o primeiro nome da tabela
tabelaComum['Nome'][0]
#conta quantas linhas a tabela tem
len(tabelaComum.iloc[0])
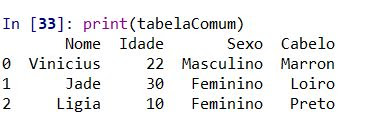
Veja abaixo como a tabela é impressa no terminal do Python
Você quer ver as versões completas desse código? Acesse nosso nosso GitHub e aproveite pra deixar aquela estrelinha em nossos repositórios.




Seria possivel pesquisar uma palavra do arquivo PDF, obter a pagina que esta palavra foi localizada?
Olá Daniel, sim é possível.
A ideia geral é você fazer uma conversão de cada página e fazer um match para verificar se a palavra está naquela página.
Tem uma discussão muito legal no stackoverflow com exemplos.
Muito bom Vinicius! Obrigada por compartilhar seu conhecimento.
Muito obrigado Regina!
Essa é a meta, compartilhar conhecimento sempre!
Tenho vários artigos em uma pasta, seria possível pegar apenas o título do artigo e colocar em um arquivo txt?
Vinicius, você sabe se é possível recuperar as partes que são imagens dentro de um PDF?
O link do github tá “quebrado”.
Obrigado
Fernando
Fala meu amigo FzGarcia!
Cara, existe sim como fazer… para isso você vai ter que aplicar uma técnica chamada OCR.
É a mesma técnica usada para transformar documentos via scanner em arquivos do word.
Infelizmente, essa técnica não é muito simples de implementar… mas fica a dica ai.
Se você quiser testar e mandar aqui pra gente, posso compartilhar com o pessoal aqui no post mesmo 🙂
Abraços