Existem muitas aplicações para o Processamento de Linguagem Natural (PLN), porém neste exercício iremos explorar uma delas que possibilita separar grupos de artigos usando PLN. Essa aplicação tem a capacidade de transformar características de um texto em uma imagem que pode auxiliar a análise do cientista de dados. A seguir descreveremos a importância de estudos de revisão e o exercício proposto.
Contexto
No campo da pesquisa é muito comum a condução de estudos para verificar quais as principais obras tratam de assuntos relacionados. Estes trabalhos ganham o nome de “trabalhos relacionados” ou “background”. Nesta seção os autores buscam entender melhor o contexto onde o seu problema de pesquisa está inserido e quais as soluções foram encontradas por outros autores.
Para realização deste estudo, uma das opções aceitas atualmente como evidência científica é a Revisão Sistemática (RS) ou Mapeamento Sistemático (MS). Este tipo de estudo segue um protocolo rigoroso de seleção que permite que os pesquisadores auditem a condução do estudo e também possam reproduzi-lo para atualizar a revisão de literatura.
Por que usar NPL em RS?
Após a realização da seleção de artigos primários o protocolo de revisão sistemática pede para que ao menos 30% da seleção seja auditada para evitar que estudos relevantes sejam excluídos por acidente. Sendo assim, o pesquisador pode optar por escolher aleatoriamente os estudos para realizar novamente a avaliação.
Já uma outra opção é utilizar uma técnica denominada Visual Text Mining (VTM). Nesta técnica o autor utiliza como entrada o conjunto de resumos que deseja-se auditar a sua classificação (incluído ou excluído). A visualização gerada permite agrupar os estudos que estão mais próximos em seu conteúdo e saber se ele foi excluído ou incluído. Veja a Figura 1:
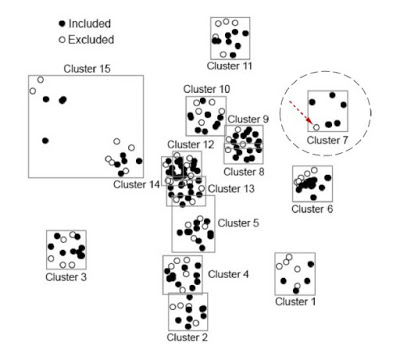
Como apontado na Figura 1, o cluster 7 possui 6 pontos que representam estudos. Dentre os estudos presentes no cluster 7 apenas 1 foi excluído. Considerando a proximidade dos conteúdos é interessante que o pesquisador realize uma nova avaliação neste estudo e considerar sua inclusão.
Veja mais como essa técnica foi aplicada neste artigo. 3- Mãos a obra: Neste trabalho você irá utilizar a linguagem Python e algumas bibliotecas para gerar estas visualizações. Recomenda-se que você instale o Jupyter notebook para melhorar sua experiência ao programar em Python.
- Para processar os resumos você poderá utilizar o NLTK como biblioteca de PLN.
- Como biblioteca de Aprendizado de máquina você pode utilizar o SciKit Learn.
- Como biblioteca para gerar as visualizações você pode utilizar o Matplotlib
- Um conjunto de estudos que você pode baixar como base de dados está disponível aqui.
- Utilize como medida de distância entre os resumos a medida do Cosseno.
3- Algumas regras do exercício:
- 1- Escolha no mínimo 3 algoritmos de clustering que melhor separem os estudos utilizados como base de dados. Veja aqui quais deles estão disponíveis no Scikit learn.
- 2- Faça alterações no número de clusters e utilize as métricas de avaliação (disponibilizadas pelo SciKit learn) para mostrar qual foi o algoritmo que teve melhor desempenho.
- 3- Veja alguns exemplos de funcionamento de alguns algoritmos aqui



