
Aprendizado supervisionado é um paradigma de aprendizado de máquina em que um modelo é treinado usando um conjunto de dados rotulado para fazer previsões ou classificações com base em entradas novas e não rotuladas.
Mas, calma lá vamos explicar isso com detalhes não é?
Os humanos aprendem de forma supervisionada?
Sim, em grande parte da nossa vida nós aprendemos de forma supervisionada recebendo exemplos de nosso pais, professores, amigos, ou seja, em quase todas as nossas relações sejam familiares e de trabalho.

Alguns exemplos de como seres humanos aprendem com supervisão são:
- Aprendizado de Linguagem:
- Quando os pais apontam para um objeto e dizem a palavra correspondente, a criança associa a palavra ao objeto, aprendendo assim o vocabulário de forma supervisionada.
- Reconhecimento de Padrões Visuais:
- Se uma criança está aprendendo a reconhecer animais, os pais podem mostrar imagens de diferentes animais e nomeá-los. A criança aprende a associar características visuais específicas aos nomes dos animais.
- Ensino Escolar:
- No ambiente educacional, os professores fornecem informações rotuladas aos alunos. Por exemplo, ao ensinar matemática, os alunos aprendem como aplicar fórmulas corretamente através de exemplos e prática supervisionada.
- Treinamento Musical:
- Um aluno aprende a tocar um instrumento musical com a orientação de um professor. O professor fornece feedback e instruções específicas para melhorar o desempenho do aluno, constituindo um processo de aprendizado supervisionado.
- Treinamento em Esportes:
- Um treinador ensina um atleta a aprimorar suas habilidades esportivas através de instruções diretas, correções e prática supervisionada. O atleta aprende a executar movimentos específicos de maneira eficaz.
- Direção de Veículos:
- Ao aprender a dirigir, um novato recebe instruções e orientações de um instrutor. O instrutor fornece feedback sobre como operar o veículo corretamente, lidar com situações específicas de tráfego e seguir as regras da estrada.
- Treinamento Profissional:
- Em ambientes de trabalho, os funcionários muitas vezes passam por treinamentos supervisionados para adquirir habilidades específicas relacionadas às suas funções. Isso pode incluir treinamento técnico, procedimentos operacionais e conformidade regulatória.
Vamos a um exemplo simples de como um humano pode aprender e generalizar alguns tópicos de forma bastante intuitiva. Vamos supor que um cientista no ano de 1670, foi em uma viagem para o centro da floresta amazônica e resolveu catalogar algumas espécies diferentes de animais.
Ao visitar o vilarejo de Tawape o cientista viu várias lagartas nos arredores do vilarejo:

Como o cientista já havia visto algumas lagartas na sua cidade natal, batizou essa lagarta com o nome do vilarejo. Ao seguir sua viagem ele também encontrou uma outra espécie, o Sapo de onogave devido a uma lenda de um Sapo que ele ouviu no folclore do seu país que fala sobre um sapo místico.

Considerando o conhecimento desse cientista, como você classificaria esse novo animal que apareceu em seu jardim?

Você como humano mal percebe o que aconteceu, porém aqui aconteceu um procedimento bastante complexo que os seres humanos se acostumaram a realizar durante a evolução. Esse processo é a generalização por meio de exemplos observados anteriormente. Algumas possíveis suposições que você poderia extrair dessas imagens:
- A imagem mostra um pequeno sapo
- Existe uma lagarta em suas costas, não há certeza se a lagarta faz parte do sapo (camuflagem) ou se é um animal separado
- O sapo mostra cores diferentes do sapo de onogave
- A possível lagarta possui uns calombos com pequenos pelos
Você percebe que existem algumas incertezas que não podemos concluir apenas com essas imagens?
Essa incerteza acontece por vários motivos e muitos deles tem a ver com a grande variedade de dados e situações no mundo real, assim, dificilmente conseguimos ter 100% de certeza com base em poucas imagens. Veja alguns motivos da nossa dúvida ao classificar essa nova foto.
- É possível que exista variações na aparência:
- As lagartas e sapos podem ter uma ampla variação em sua aparência, mesmo dentro da mesma espécie. Fatores como idade, ambiente, e estágio de desenvolvimento podem afetar significativamente a aparência.
- As imagens usadas podem não mostrar a realidade com qualidade:
- Se as imagens usadas para treinar o modelo não representam adequadamente a diversidade de características presentes nas lagartas e sapos, a IA pode não ser capaz de generalizar bem para novas imagens.
- Variação na Posição e Iluminação:
- A posição da câmera, iluminação e fundo das imagens de treinamento podem afetar a capacidade do modelo de generalizar para novas condições. Se a nova imagem for tirada em condições diferentes, a incerteza pode aumentar.
- Overfitting:
- Se o nosso cientista foi treinado apenas para reconhecer especificamente alguns tipos de animais, o conjunto de dados é muito específico e pequeno. Assim, ele pode se tornar excessivamente ajustado (overfit) a esses dados, tornando-se menos capaz de lidar com casos mais amplos e variados.
- Ausência de Informação de Contexto:
- Sem informações contextuais adicionais, como comportamento, ambiente e outros detalhes específicos, a IA pode ter dificuldade em fazer predições mais precisas.
- Ruído nos Dados:
- Ruídos ou perturbações nas imagens de treinamento podem levar a interpretações erradas ou incertas. Isso é especialmente relevante quando se lida com dados do mundo real.
Exemplo prático de aprendizagem supervisionada
O Teachable Machine é uma ferramenta desenvolvida pelo Google que permite aos usuários treinarem modelos de aprendizado de máquina sem a necessidade de conhecimento avançado em programação ou ciência de dados. Lançado como uma plataforma acessível e amigável, o Teachable Machine possibilita que pessoas sem experiência técnica explorem e compreendam os conceitos fundamentais de machine learning de maneira prática. Os usuários podem treinar modelos usando exemplos visuais, de áudio ou gestuais, fornecendo dados de entrada e saída para ensinar a máquina a reconhecer padrões e realizar tarefas específicas. Isso democratiza o acesso à tecnologia de aprendizado de máquina, permitindo que pessoas de diversas áreas explorem as potencialidades dessa área em suas próprias aplicações criativas, educacionais ou de desenvolvimento de projetos.
No Teachable Machine, os usuários podem treinar modelos para classificar e reconhecer padrões em dados de entrada personalizados. Isso é feito por meio de uma interface intuitiva, onde os usuários alimentam o modelo com exemplos de diferentes classes e, em seguida, testam sua capacidade de generalização em novos dados. O aprendizado de máquina por trás da ferramenta é simplificado para permitir uma experiência de usuário amigável, tornando o processo de treinamento de modelos mais acessível. O Teachable Machine ilustra a tendência crescente de tornar a inteligência artificial mais compreensível e utilizável por um público mais amplo, incentivando a experimentação e a inovação em diversas áreas por meio do poder do aprendizado de máquina.
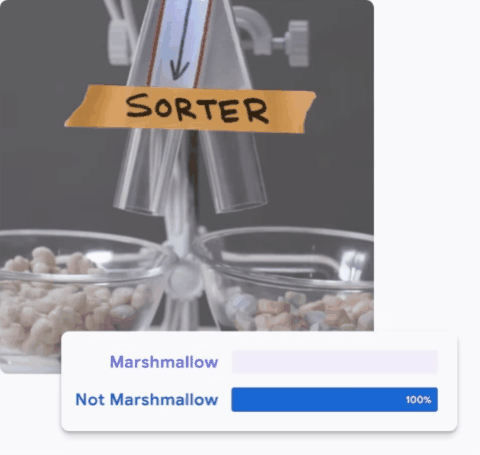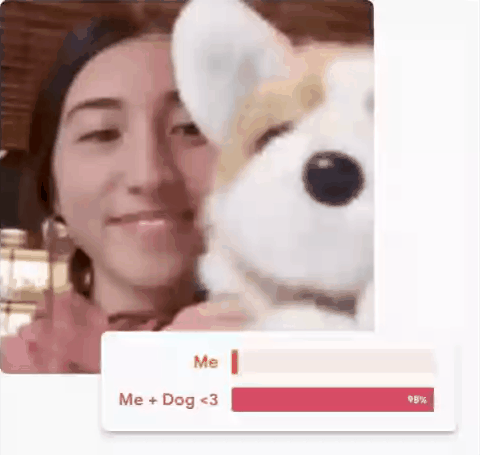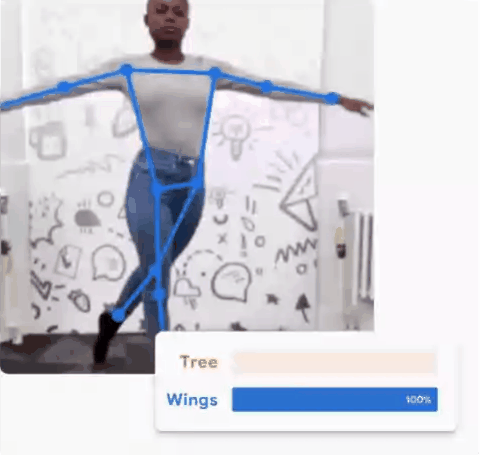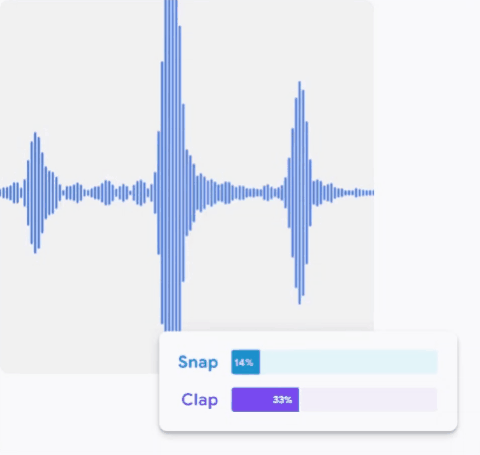
Treinando o seu próprio modelo no Teachable Machine
Entre no website do teachable machine:
Clique no botão “Get Started”
Se você estiver logado na sua conta google você será automaticamente redirecionado para página inicial da ferramenta. Caso contrário você deverá fazer logon na sua conta Google.
A tela principal deve é essa:
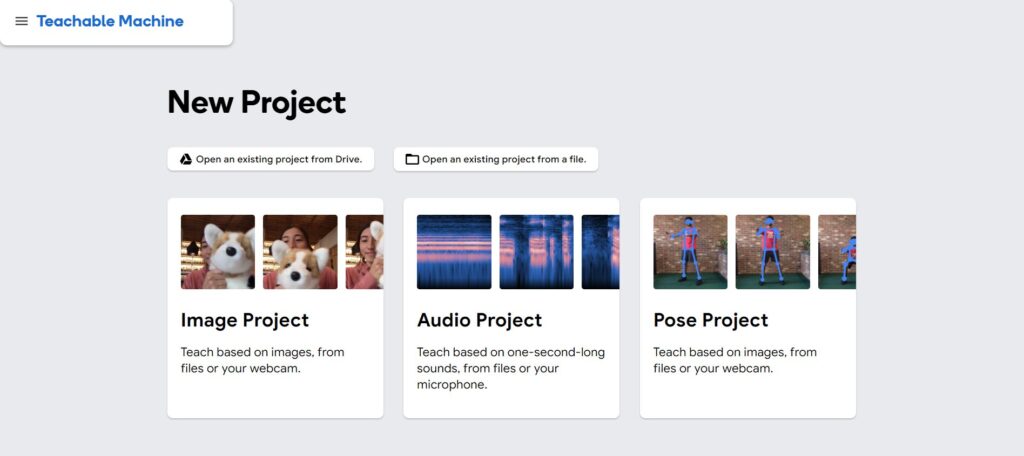
Agora você poderá escolher dos tipos de projeto, para esse exemplo vamos fazer um “image project”:

Ao clicar você será solicitado para escolher qual tipo de imagem você quer usar. Aqui você pode escolher o padrão (melhor para computadores) e se você quiser usar em microcontroladores como arduino ou ESP32 você pode usar o embedded image model. Por agora vamos ficar com o padrão.
A interface de treinamento do seu modelo é essa:
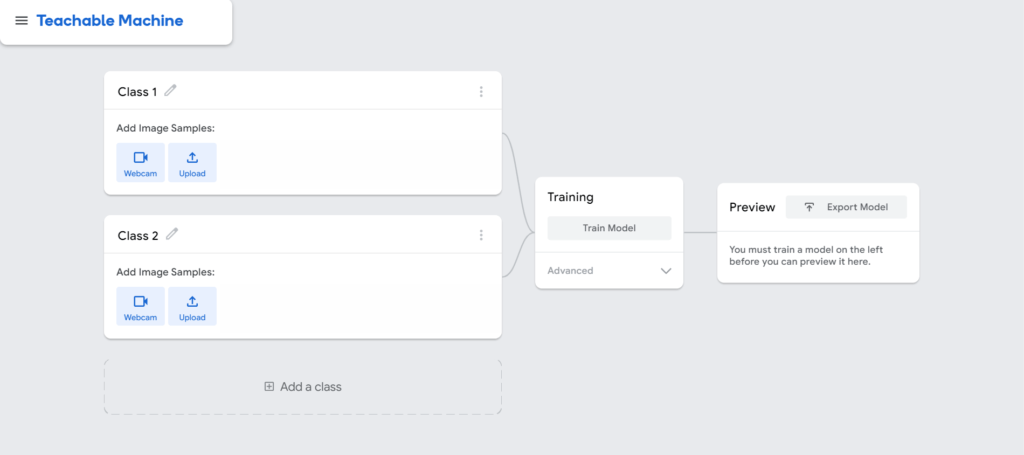
Agora é a hora do nosso treinamento, vamos criar duas classes: cachorro e gato. Essas duas classes serão carregadas com o dataset “cães e gatos” do Kaggle. Essas imagens servirão como uma forma de “exemplo” para ensinar nosso algoritmo a identificar o que é um gato e um cachorro.
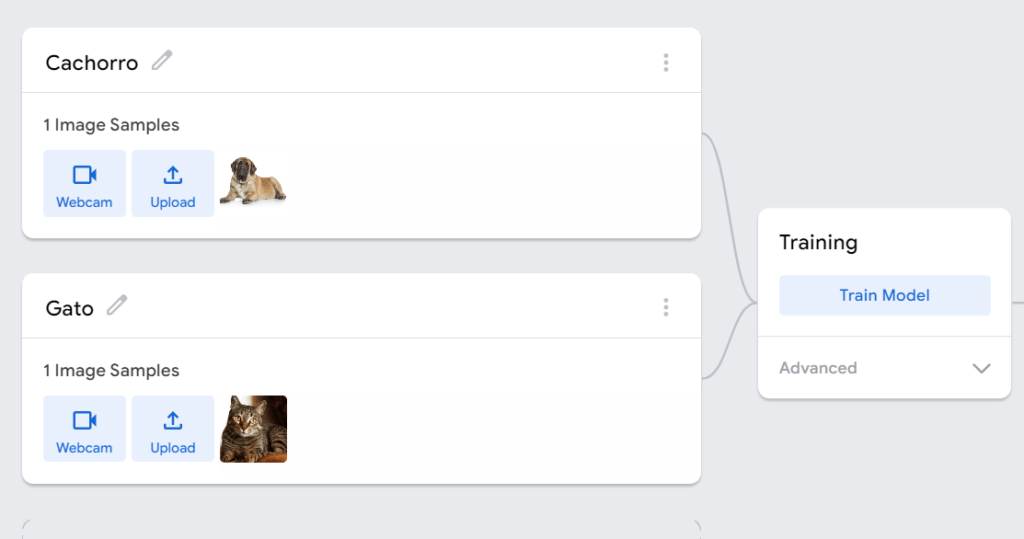
Depois de adicionar as fotos vamos clicar em “Train Model”. Após o treinamento temos o modelo pronto para ser pré visualizado.
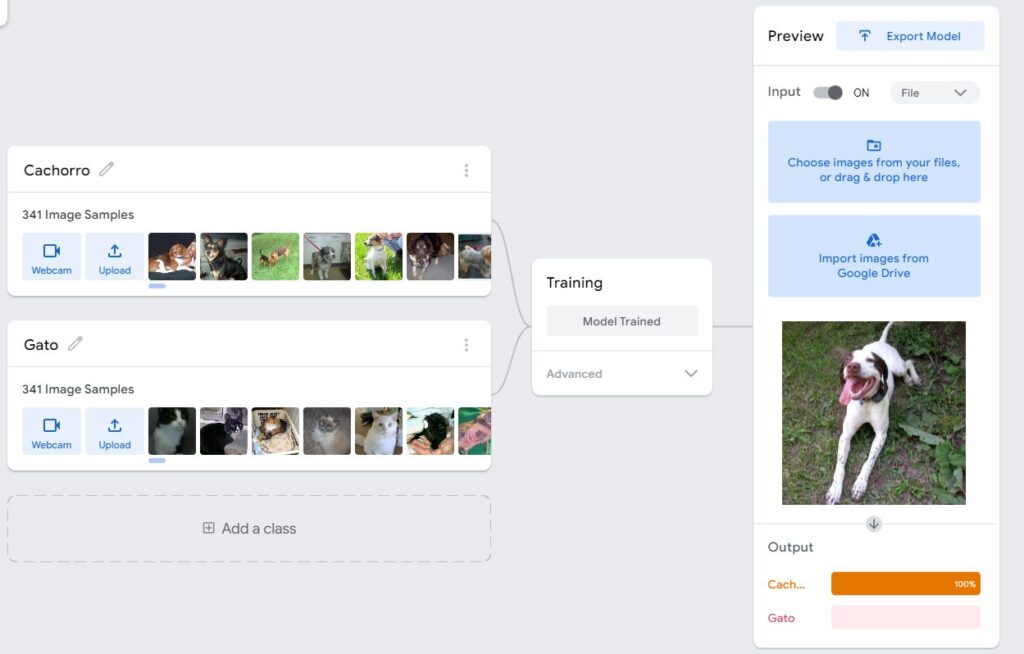
Clique em “Choose images from your files” e adicione a foto de um cachorro ou de um gatinho e observe o resultado. Ao dar ao sistema um novo exemplo ele consegue classificar se aquilo é realmente um cachorro ou um gato.
Como poderiamos aplicar esse tipo de aprendizado na indústria?
Usando esse tipo de abordagem poderiamos criar uma máquina capaz de realizar classificação de diferentes tipos de imagem de forma bastante assertiva. Na indústria 4.0. esse tipo de classificação poderia ser implementado, por exemplo, para separar tomates maduros de tomates verdes. Veja a seguir uma aplicação desse conceito:
Porém, sabemos também que essa tecnologia não é aplicada apenas na área da agricultura. As indústrias também de processamento de alimentos podem utilizar essa tecnologia para detectar problemas em frutas:
O que é um conjunto de dados?
Um conjunto de dados no contexto de Inteligência artificial é um conjunto de dados que foram cuidadosamente selecionados para servir de exemplo para o aprendizado de uma IA. Cada exemplo no conjunto de dados é composto por uma entrada e a saída correspondente que o modelo deve aprender a prever.
- Entrada (características): São as variáveis ou características que são fornecidas como entrada para o modelo. Por exemplo, se estivermos construindo um modelo para prever a nota de um aluno com base no número de horas de estudo, a entrada seria o número de horas de estudo.
- Saída (rótulo ou alvo): É a variável que o modelo tenta prever. Continuando com o exemplo anterior, a saída seria a nota real do aluno.
Os dados de treinamento de uma IA não necessariamente são imagens (como no nosso exemplo anterior), frequentemente, esses dados são expressos por meio de números, categorias, texto, dados temporais, binários, localização e também de audio e vídeo.
Dados Numéricos:
- Contínuos: Números que podem assumir valores em uma faixa contínua (por exemplo, altura, peso).
- Discretos: Números inteiros ou contáveis (por exemplo, número de filhos, número de produtos vendidos).
Dados Categóricos:
- Nominais: Categorias sem uma ordem específica (por exemplo, cores, tipos de animais).
- Ordinais: Categorias com uma ordem específica (por exemplo, classificação de satisfação, níveis de educação).
Dados de Texto:
- Informações em formato de texto ou strings (por exemplo, descrições, comentários).
Dados Temporais: Informações relacionadas a datas e horários (por exemplo, timestamps, datas de eventos).
Dados Binários: Variáveis que têm apenas dois valores possíveis (0 ou 1, verdadeiro ou falso).
Dados Geoespaciais: Informações relacionadas a localizações geográficas (por exemplo, coordenadas geográficas, endereços).
Dados de Imagem e Vídeo: Informações visuais em forma de imagens ou vídeos.
Veja um exemplo abaixo de como podemos encaixar esses tipos de dados em uma tabela:
| ID | Nome | Idade | Altura | Núm. Filhos | Cor Fav. | Classificação Satisfação | Descrição Pessoal | Timestamp | Cliente Ativo | Coordenadas Geográficas | Cartão de Fidelidade | Imagem de Perfil |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Maria | 28 | 1.65 | 2 | Azul | Bom | “Extrovertida” | 2023-01-10 08:30:00 | Sim | (40.7128, -74.0060) | Sim | Link |
| 2 | João | 35 | 1.80 | 1 | Verde | Excelente | “Esportes radicais” | 2023-01-12 15:45:23 | Não | (34.0522, -118.2437) | Não | Link |
| 3 | Ana | 22 | 1.55 | 0 | Vermelho | Regular | “Estudante de Artes” | 2023-01-15 12:10:45 | Sim | (41.8781, -87.6298) | Sim | Link |
| 4 | Carlos | 40 | 1.75 | 3 | Amarelo | Excelente | “Empresário e viajante” | 2023-01-20 09:20:12 | Sim | (51.5074, -0.1278) | Sim | Link |
Criação de Rótulos
O processo de criação de rótulos, também conhecido como rotulação de dados, é uma etapa crucial em muitos problemas de aprendizado supervisionado. A rotulação envolve atribuir etiquetas ou rótulos aos dados de treinamento para que o algoritmo de aprendizado de máquina possa aprender a relação entre as entradas (características) e as saídas desejadas (rótulos).
Antes de mais nada, precisamos compreender o problema em questão. Assim podemos ter total domínio de quais são as saídas desejadas para as entradas específicas. Por exemplo, se estiver trabalhando em um problema de classificação de imagens, você precisa saber quais categorias ou classes as imagens devem ser rotuladas (igual fizemos no exemplo anterior).
Seleção dos Dados de Treinamento:
- O conjunto de dados selecionado usado para treinar o modelo deve ser representativo, ou seja, esses dados de treinamento devem abranger a diversidade de casos que o modelo encontrará na prática.
Atribuição de Rótulos:
- Para cada exemplo no conjunto de dados de treinamento, atribua manualmente ou automaticamente o rótulo correspondente. No aprendizado supervisionado, os rótulos representam as saídas desejadas associadas às entradas.
Oráculos
O termo “oráculo” refere-se a uma fonte externa de conhecimento ou um sistema que fornece respostas corretas ou rótulos para dados específicos. O oráculo é usado principalmente em situações em que é necessário obter rótulos ou feedbacks corretos para treinar ou avaliar um modelo de aprendizado de máquina.
Vamos considerar um exemplo prático de como usar um oráculo em um problema de aprendizagem supervisionada para classificar peças como defeituosas ou não defeituosas. Neste caso, o oráculo será um especialista humano que pode rotular corretamente as peças.
Coleta de Dados:
- Um conjunto inicial de imagens de peças é coletado para treinar um modelo de aprendizado de máquina. Essas imagens são rotuladas como “Defeituosa” ou “Não Defeituosa”.
Treinamento Inicial:
- Um modelo de aprendizado supervisionado, como uma rede neural convolucional, é treinado usando o conjunto inicial de dados rotulado.
Aprendizado Ativo com Oráculo:
- O modelo é usado para prever a classe (defeituosa ou não defeituosa) de um conjunto de peças não rotuladas. Em vez de rotular todas as peças imediatamente, o modelo seleciona algumas peças em que tem menor confiança e pede ao oráculo (especialista humano) para fornecer rótulos corretos.
Atualização do Modelo:
- Com os novos rótulos fornecidos pelo oráculo, o modelo é atualizado com os dados rotulados adicionais. Isso ajuda o modelo a ajustar suas previsões, melhorando sua capacidade de generalização.
Iteração:
- O processo de aprendizado ativo com o oráculo pode ser repetido várias vezes, selecionando sistematicamente as instâncias em que o modelo tem menor confiança. Cada iteração envolve a obtenção de rótulos corretos do oráculo e a atualização contínua do modelo.
Avaliação e Uso em Produção:
- Após várias iterações, o modelo é avaliado em um conjunto de validação ou teste. Uma vez que o desempenho é satisfatório, o modelo treinado pode ser implantado em produção para classificar novas peças como defeituosas ou não defeituosas automaticamente.
Neste exemplo, observamos que o oráculo desempenha um papel fundamental na correção de erros do modelo e na melhoria contínua do desempenho, especialmente em situações em que o modelo pode ter dificuldade em casos ambíguos. O aprendizado ativo com o oráculo permite uma abordagem mais eficiente e focada na melhoria do modelo, economizando tempo e recursos.


