
O assunto do momento é mineração de dados e Machine Learning (aprendizado de máquina) e aparentemente o mundo despertou para a infinidade de possibilidades que emergem desse tópico. Antes de qualquer coisa, precisamos dizer que esse tópico começou a ser descoberto pela ciência já faz bastante tempo. Existem artigos da década de 60 falando sobre redes neurais, uma técnica que recentemente se tornou muito popular.
Nesse artigo não vamos entrar na questão do que é inteligência e o que não é considerado inteligência. Existem vários autores que gostam muito de discutir filosoficamente esse assunto, porém, esse não é nosso foco. Na verdade nosso foco é mostrar que existem várias abordagens diferentes de IA para que podem solucionar uma grande variedade de problemas.
Se você gosta de saber mais sobre ciência de dados não esqueça de ver nossos conteúdos gratuítos sobre esse assunto.
O que é aprendizado de máquina (Machine Learning)?
Os algoritmos de aprendizado de máquina são programas que tentam encontrar padrões em um conjunto de dados. Assim como mencionamos anteriormente, esses algoritmos já estão sendo estudados no campo da computação há muito tempo, porém, a grande diferença é que atualmente existe uma gigantesca massa de informações que precisa ser tratada (o que antes não existia). Isso aconteceu graças a dois fatores: a informatização em massa e o surgimento da Internet.
Agora em um papo mais de tiozão, na época que a sua melhor oportunidade para compartilhar algo com alguém era usando mídias físicas, a possibilidade de você construir uma recomendação automática eram bem limitadas. Toda mídia que não estava no seu computador, em verdade não existia. Isso tudo mudou muito com a internet e também do processamento de dados em nuvem, atualmente, você sincroniza tudo que quiser com seus dispositivos e não tem mais a necessidade de usar nenhuma mídia física. Até os videogames não possuem mais mídia física, agora tudo é online.
As máquinas que aprendem nada mais são do que programas que “aprenderam a aprender”.
Tá bom, acho que eu comecei a pirar com esse assunto, mas calma, respira…
O aprendizado é na verdade uma forma com que o nosso cérebro começa a reconhecer coisas, armazená-las e também recuperá-las. Por exemplo se você vê um cachorro, automaticamente você vai saber que se trata de um cachorro, mas isso só acontece porque durante a sua vida inteira você viu muitos exemplos de cachorros por ai e também alguém te ensinou que aquilo tem o nome de cachorro.
Outra coisa que é possível que você faça é reconhecer alguns padrões e separar grupos. Imagine por exemplo que você tem uma cesta cheia de bolas de tênis, ping-pong e bolas de gude. Não é difícil pra você (mesmo que você nunca tenha visto nenhuma delas) separá-las em grupos. Isso acontece por que cada uma possui características muito específicas e fáceis de identificar.
Tipos de aprendizado de máquina
Inspirando-se no aprendizado humano os programadores também conseguiram compreender que poderiam “ensinar” as máquinas a aprender. Para isso, foi preciso vários e vários anos de evolução na ciência e principalmente da estatística.

Muita gente diz amar Machine Learning e IA, porém torce o nariz quando o assunto é estatística e matemática. Não faz muito sentido, visto que os métodos de ML e IA são baseados puramente em estatística.
O que é aprendizado supervisionado?
Aprendizado supervisionado é uma forma de aprendizado de máquina onde os algoritmos aprendem através de exemplos e depois podem fazem previsões com base em um modelo. Por exemplo, imagine que você precisa aprender a reconhecer uma cadeira com defeito. Primeiramente, você vai falar com um especialista em cadeiras que vai te mostrar todas as características de uma cadeira e depois você irá passar horas em um treinamento observando os defeitos possíveis das cadeiras. Após toda essa jornada, você finalmente está apto a começar a classificar cadeiras com defeito.
Pode parecer um exemplo bobo, mas pense agora na bolsa de valores. Imagine se você pudesse observar historicamente os fatos e buscar inferir a variação das ações com base nisso. Seria uma ideia incrível não é? Pois é assim que a maioria das transações são feitas hoje, com base em análise de dados do mercado financeiro.
Há vários tipos específicos de aprendizado supervisionado, por exemplo: classificação, regressão e detecção de anomalias.
- Classificação. esse tipo de aprendizado é usado quando os dados estiverem sendo usados para prever uma categoria. Imagine por exemplo que você precisa atribuir a uma imagem como uma foto de um ‘gato’ ou de um ‘cachorro’ um rótulo. Quando há apenas duas opções, isso é chamado de classificação binomial ou de duas classes. Quando houver mais categorias o problema é conhecido como classificação multi-classe.
- Regressão. Quando um valor estiver sendo previsto, assim como acontece com preços de cotações, o aprendizado supervisionado será chamado de regressão.
- Detecção de anomalias. Às vezes, o objetivo é identificar os pontos de dados que são simplesmente incomuns. Esse é um clássico exemplo da detecção de fraudes, por exemplo, padrões incomuns de gasto em cartão de crédito são suspeitos. Essa técnica é muito interessante devido ao número gigantesco de possibilidades de variações de atividades fraudulentas, sendo assim, é mais fácil verificar anomalias. A abordagem que usa detecção de anomalias é simplesmente aprender como seria uma atividade normal (usando transações não fraudulentas históricas) e identificar tudo que seja significativamente diferente.
O que é aprendizado não supervisionado?
O aprendizado sem supervisão (também chamado de automático) é uma forma de aprendizado em que a máquina tenta inferir uma informação com base em uma estrutura oculta ou características de dados “não marcados”. Lembra daquela frase antiga: “diga com quem anda e te direi quem é”? É mais ou menos isso que acontece.
A grande diferença aqui é que os dados nesse tipo de aprendizado não tem anotação (o que ajuda muito quando o volume de dados é grande), porém, não há avaliação da precisão da estrutura que é produzida pelo algoritmo.
Alguns exemplos de abordagens utilizadas no aprendizado não supervisionado:
- Clustering
- k-means
- hierarchical clustering,
- anomaly detection
- Redes neurais
- Generative Adversarial Network – Quer saber mais? veja esse nerdcast maravilhoso.
Vamos a um exemplo bem simples que nós postamos em nosso instagram:

Obrigado Diego Nogare pelas imagens. 




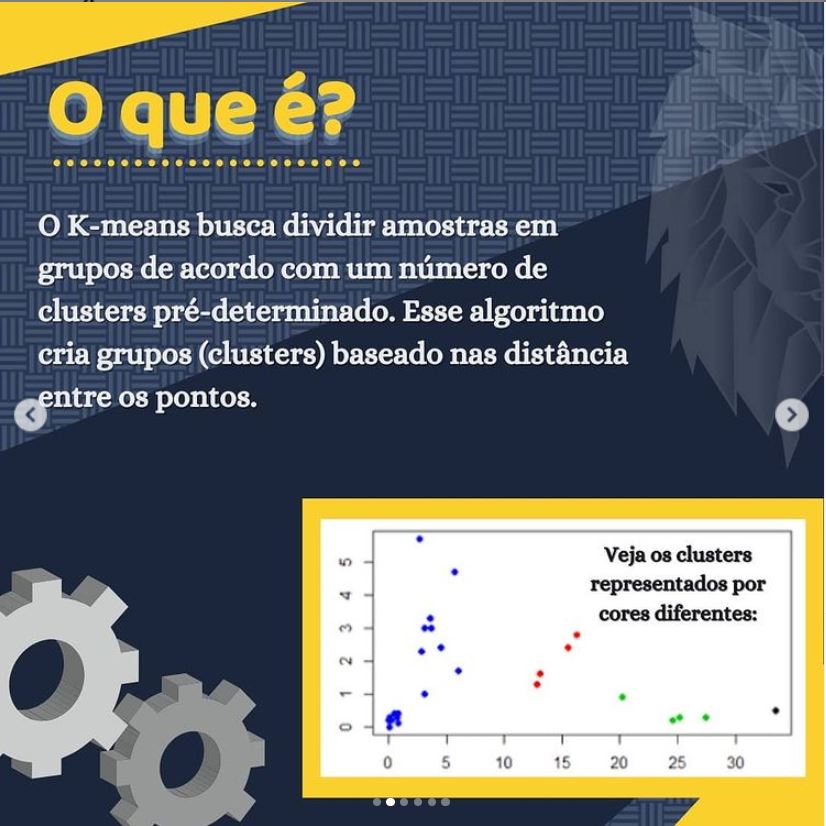

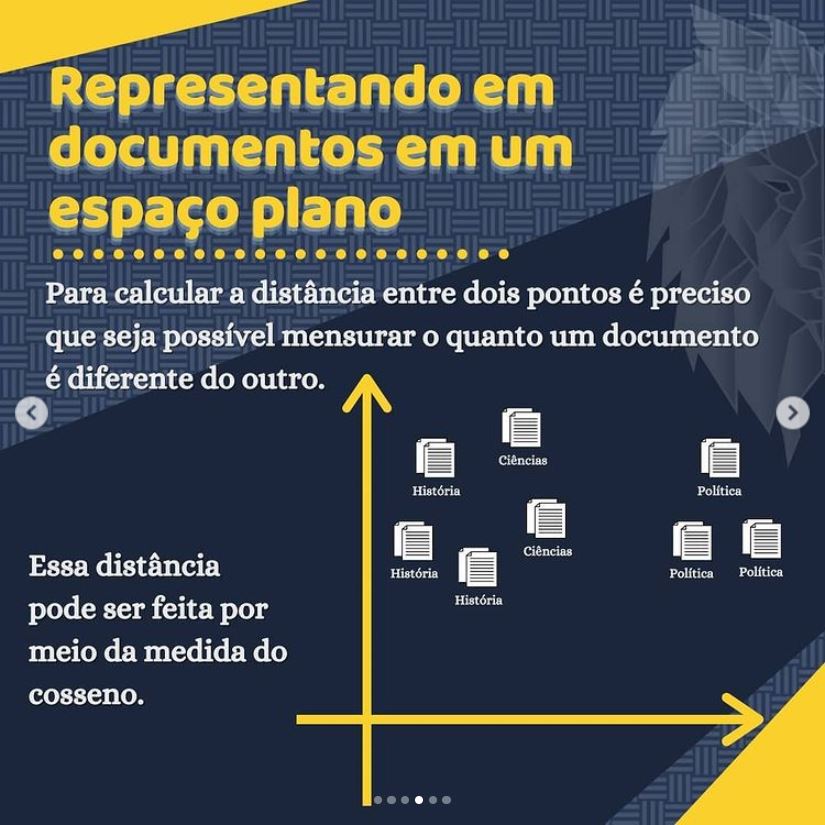
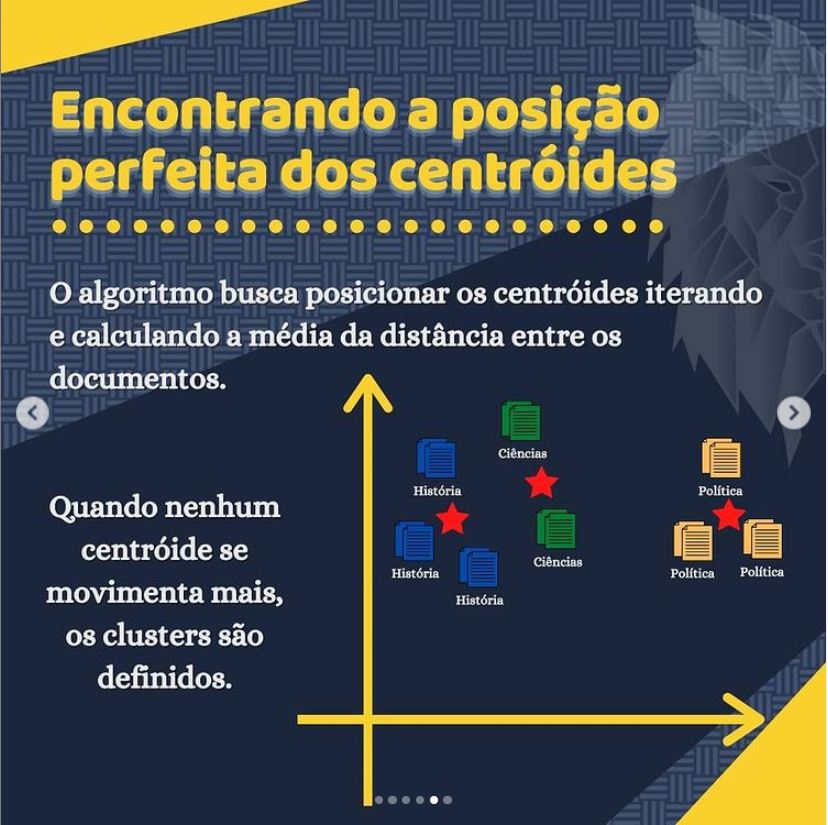
Como podemos perceber a meta de um algoritmo de aprendizado sem supervisão é organizar os dados de alguma forma ou descrever sua estrutura. Isso pode significar agrupá-los em clusters ou encontrar diferentes maneiras de consultar dados complexos para que eles pareçam mais simples ou mais organizados.
O que devemos considerar ao escolher um algoritmo?
Não existe um algoritmo específico para cada situação, não existem regras fixas que você segue e pronto. Por isso a ciência de dados é tão complexa e os salários são tão altos. Por isso você precisa analisar alguns parâmetros para escolher um algoritmo:
Acurácia e Precisão
A acurácia e precisão são medidas que refletem a quantidade de “acertos” que um algoritmo tem ao tentar classificar um novo exemplo. A acurácia é reflete a quantidade de vezes que o algoritmo acertou a classificação correta e a precisão é quantidade de vezes que o algoritmo foi consistente em suas previsões.
Veja o exemplo:
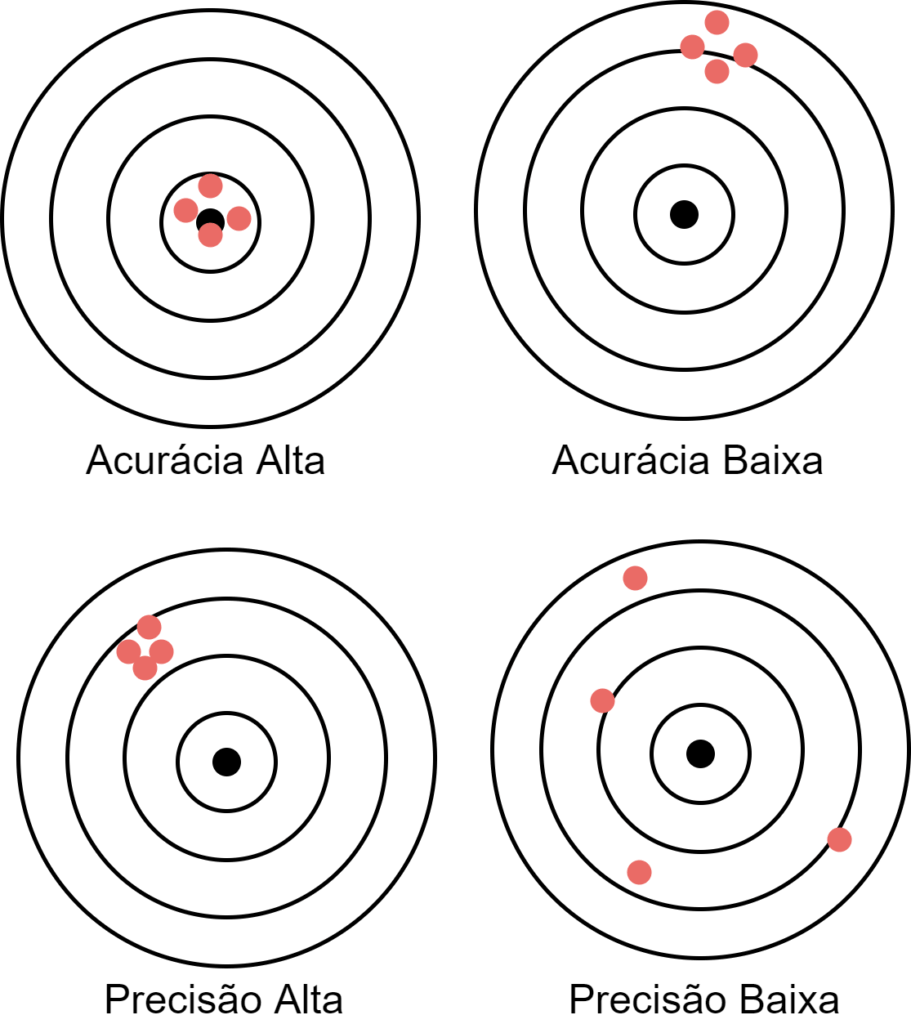
Nem sempre é necessário obter a resposta mais precisa, em algumas situações usar uma aproximação é melhor dado a quantidade de tempo necessária para treinar um algoritmo ou executar uma previsão.
Tempo de treinamento
Um fator muito importante é o número de minutos ou de horas necessários para treinar um modelo varia muito entre algoritmos. Em geral, o tempo de treinamento está intimamente vinculado à precisão — um normalmente acompanha o outro. Além disso, alguns algoritmos são mais sensíveis ao número de pontos de dados do que outros. Quando o tempo for limitado, ele poderá orientar a escolha do algoritmo, especialmente quando o conjunto de dados for grande.
Linearidade
Muitos algoritmos de aprendizado de máquina usam a linearidade e supõem que as classes podem ser separadas por uma linha reta (ou seu análogo em dimensões maiores). Isso inclui a regressão logística e as máquinas de vetor de suporte. Os algoritmos de regressão linear supõem que as tendências de dados seguem uma linha reta. Essas suposições não são ruins para alguns problemas, mas em outros elas podem reduzir a precisão.
Número de parâmetros
Os parâmetros são importantíssimos para escolher seu algoritmo de Machine Learning, eles basicamente são as informações que são necessárias fornecer ao algoritmo para que o resultado seja o melhor possível. Esses números definem como o algoritmo se comportará, por exemplo, como será a tolerância com erros ou então o número de iterações que serão executadas. O tempo que leva para o algoritmo conseguir realizar o treinamento pode ser muito alto, em geral aqueles que tem um grande número de parâmetros exigem mais tentativas e erros para a localização de uma boa combinação. Existem ainda vantagens em ter muitos parâmetros, geralmente indica que um algoritmo tem mais flexibilidade. Geralmente, isso pode significar uma precisão muito boa. Desde que você consiga encontrar a combinação certa de configurações de parâmetro.
Número de recursos
O numero de recursos é essencial para determinar o algoritmo a se adotar. Geralmente o grande número de recursos necessários para treinar um modelo reduz a quantidade algoritmos de aprendizado de máquina que podem ser usados. Isso acontece porque o tempo de treinamento é impraticável.
Conclusão
Certa vez estava estudando estes algoritmos em um curso rápido e presencial e buscava a resolução para um problema específico no qual trabalhava. Tive a audácia de perguntar ao professor se havia indicações de que determinado algoritmo resolveria meu problema. O professor sem pestanejar disse: “Aprenda uma coisa, em Inteligência Artificial não existe lanche grátis”. Ele disse isso fazendo referência a uma expressão norte americana que quer dizer: “Não existe”. Neste dia eu aprendi que nada nesta área é tão pronto que não mereça uma boa análise antes de se aplicar um algoritmo.
Fontes:
https://docs.microsoft.com/pt-br/azure/machine-learning/machine-learning-algorithm-choice
https://www.manualdousuario.net/inteligencia-artificial-aprendizado-de-maquina/


